You’ve heard this before. The team has been working on this service and a couple months later traffic is picking up. Pretty awesome you think, customers are loving this feature! Hold on, now you hear finance people screaming at the Amazon bill. The application is considerably resource intensive. You got two options: 1) find the bottleneck and optimize, 2) limit cost of running the service. Let’s focus on the latter.
Welcome to Amazon Auto Scaling. If the fundamental premise of the cloud is “use only the resources you need for as long as you need”, then add “dynamic scaling based on traffic”. Bottom line: you save money when traffic is low. Enterprise SaaS is a great use case since customers are using your product during typical business hours, resulting in very low traffic at night. So what does it take to make the switch?
Stateless VS stateful application
Ideally you want to be dealing with a stateless application, where terminating one node won’t produce side effects on user experience. Typical stateless apps include frontend web servers or any app that doesn’t rely on keeping session state in memory.
Unfortunately not all software is created equal. Our use case is a video recorder for web based meetings. While the presenter is discussing slides, the recorder is watching the presentation unfolding real time.
Try to terminate one instance with active sessions and you’re impacting user experience. But there is a solution to which we’ll come back shortly.
Prerequisites
One thing with dynamically terminating instances is that you can’t rely on SSH access any longer:
- Logs need to be forwarded to a remote host using Elasticsearch, Splunk or similar.
- Provisioning an instance is done in an automated fashion. We use Chef and Terraform.
- Not directly related to Auto Scaling here but proper deployment tooling is also a requirement. We use Jenkins pipelines and Chef.
Architecting the app around Auto Scaling
Our video recorder app went through a few changes. First you need to expose a health check endpoint that returns HTTP 200 if the app is in a good state. Amazon is continuously polling it and will replace unhealthy instances.
Then you need the app to properly report your chosen autoscaling metric to CloudWatch. For instance our metric is “number of running jobs”. A java thread can handle the task or even a cron job.
One more thing about stateful applications: we want to make sure we don’t disrupt running jobs during a scale down event. Amazon conveniently provides Lifecycle Hooks which allows to perform a custom action before terminating the instance. For instance: a decrease in traffic triggers a scale down event. The oldest instance (by creation time) is picked and moves to Termination:Wait state. Amazon sends a notification using SNS to check if the instance is ready to be terminated. The instance gets the notification and will give the green light for termination if there is no job running, otherwise it’ll respond with a heartbeat to keep waiting until all jobs are done. Which means your app needs to have a thread listening to SNS notifications.
Interestingly lifecycle hooks cannot be set up on Amazon web console, you'll have to use the CLI.
Amazon SDKs make it pretty straightforward to implement the above two items.
Capacity planning
Our video recorder app is mostly CPU bound, so ideally you want to keep CPU load no higher than 50%. The goal is to have enough capacity to be ready for traffic peaks in the morning, and remove instances as traffic slows down at end of the day.
Auto Scaling policies are designed around a specific metric. If you’re working with a queue based model then scaling will be done based on the SQS queue size, otherwise we’ll use the custom metric “number of running jobs”.
Good scale up policies tend to be more aggressive in terms of instance count to add. In our case we set the scale up policy to “Add 2 instances when average jobs per instance is => 3”. Given that our minimum instance count is 4 we’ll trigger a scale up as soon as we hit 12 simultaneous jobs, which does happen early in the morning.
Regarding scale down, it’s best to be more conservative as we want to make sure we aren’t falling short in the middle of a good traffic period. In other words, better to remove instances whenever those are doing nothing. We set our scale down policy to “Remove 1 instance when average jobs per instance =< 1”
Also make sure that both policies are compatible with each other. For instance: scale up is triggered with 12 jobs and we go from 4 to 6 instances. If scale down is triggered when hitting an average of 2 jobs per instance, which we do now, then we immediately scale back down.
Lessons learned
- Scale up and scale down events are not independent. One needs to fully complete before the next one can execute. This can be dangerous in the case where a scale down event is triggered, putting the instance in Termination:Wait state until all jobs are done running. The instance can easily stay in that state for 45min sometimes. If you have a simultaneous traffic peak you risk running out of capacity as you won’t be able to increase the cluster size before 45min.
- No new requests are sent to the instance when it’s in Termination:Wait state. This is true when using ELB at least, as Amazon support confirmed. This allows for safe connection draining.
- Fundamental system metrics matter. A few things came up while transitioning our recorder app to Auto Scaling mode, one of them being CPU overuse. It can be easy to lose track of simple things with the ephemeral nature of instances. We made sure to have alerts set up for CPU usage, load average and RAM usage.
- One more side effect of ephemeral instances is that local data is lost upon instance termination which makes it harder to troubleshoot customer issues. One solution is to proactively store any useful data in S3. We dealt with it by setting up proper Splunk alerts which would bubble up any serious looking issue. Then we’d investigate on the box and retrieve any relevant data.
- Watch out for Amazon Limits. Those are limiting the quantity of instances, among other things, that can be spun up within a region. As your Auto Scaling cluster grows or if you have multiple clusters in one region, you’ll likely face the limit sooner or later. Make sure to raise the limits to a high ceiling ahead of time, and subscribe to email notifications. We got bitten once when EBS volumes maxed out.
Instrumentation is everything
The key to a successful Auto Scaling transition is proper instrumentation. We made a detailed dashboard showing instance count, job count, unhealthy hosts on ELB, average job count per instance. It helps uncover patterns and confirm existing ones.
Here is an overview of a typical business day:
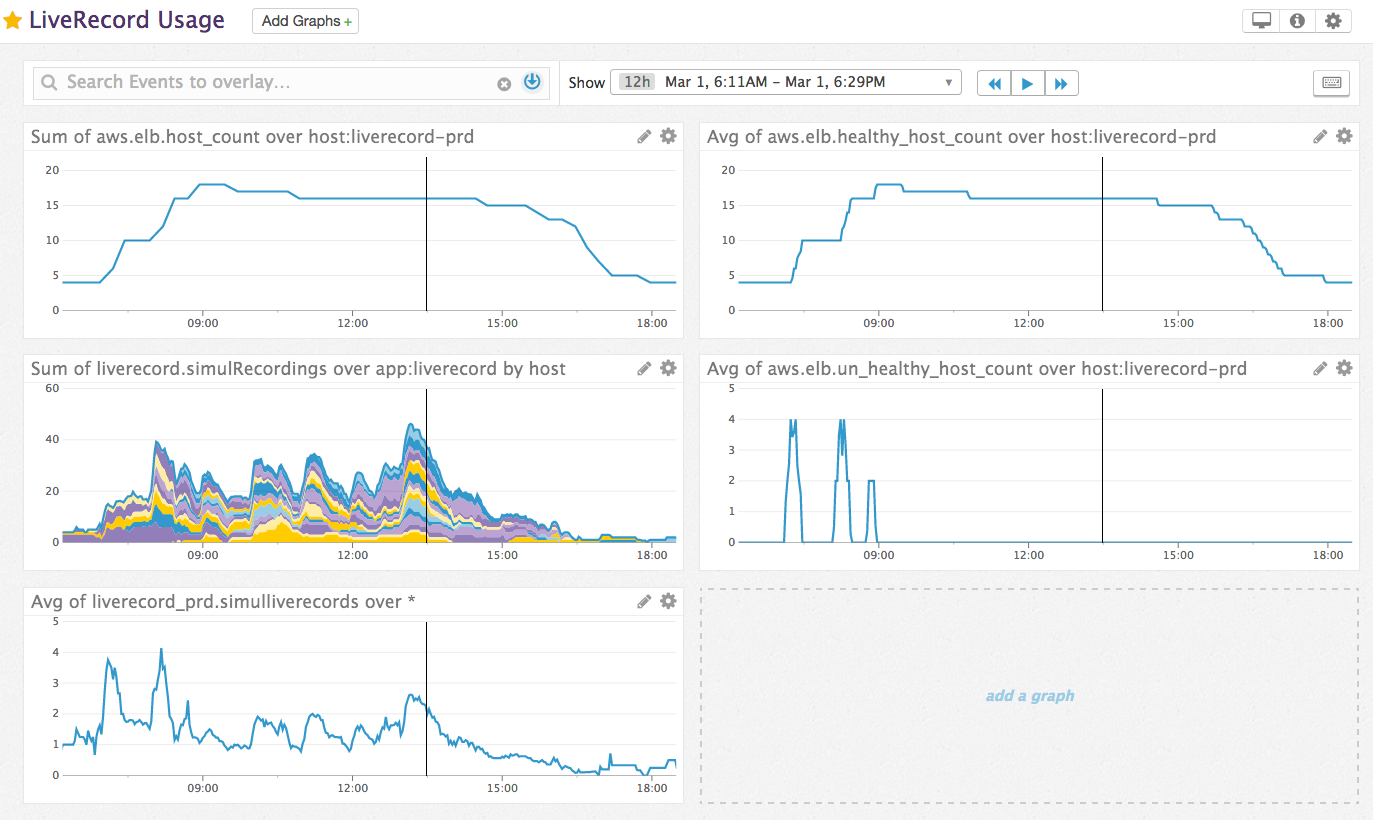
Most important things to notice on the upper right corner graph is the scale up in the early morning traffic as well as the cascading scale down in mid afternoon. It clearly demonstrates the impact of Auto Scaling during key business hours.
Another important graph is the middle left “simulRecordings”. Each color represents a different instance, which means the sooner the color count increases the sooner we have scaled up and spread traffic out. We can also spot new traffic peaks.
Finally the one on the bottom left corner allows for a reality check of Auto Scaling rules. As the average job count per instance increases, we should expect to see scale up activity in the upper right corner graph.
We highly recommend using StatsD to report application metrics as it’s the easiest and there is libraries for all languages.
In closing, it’s also worth considering the tradeoff of refactoring the application versus using Auto Scaling. As we’ve seen the Auto Scaling lifecycle will bring along its complexities. Sometimes it makes sense to refactor the app into a lighter version. One last thing to keep in mind is instance provisioning time. It pays off to keep provisioning time to a minimum in order to keep scaling movements seamless. Ideally you want to have a pre-packaged AMI ready to start, which allow for a total startup time under 1min30s. Another reason to use such AMIs is to reduce runtime downloading of dependencies (can happen sometimes with Chef). Dependencies can be in a bad state and an auto-scaled instance might never be able to successfully boot-up. Packer is a great tool for this and integrates easily within your existing workflow.
Special thanks to Kartick Suriamoorthy for his support and proofreading, and ClearSlide for the opportunity to work on this great project.